Mes: julio 2007

Un artículo de la revista La Cartelera nos ofrecía en 2005 detalles del trabajo que se realiza en la Filmoteca Valenciana fundada en 1987 para la conservación de la memoria audiovisual valenciana. Actualmente, el Institut Valencià de Cinematografia (IVAC) conserva más de 10.000 documentos en su archivos entre originales de películas, copias de exhibición y filmes de aficionados.
Sus instalaciones están situadas en el Parque Tecnológico de Paterna (Valencia) donde se distribuyen cinco salas en forma de archivo que se encuentran a medio camino entre búnker acorazado y cámara frigorífica. Sólo allí se puede garantizar que los fotogramas grabados puedan perdurar al paso del tiempo ajustándose las condiciones de temperatura y humedad óptimas.
Ortifus me recomienda que me pasee por la bitácora del humorista gráfico valenciano Malagón y esto es lo que me he encontrado correspondiente al 26 de enero de 2007.

Primera Guerra Mundial: 28 de julio de 1914 – 11 de noviembre de 1918

Soldados americanos leyendo libros en una biblioteca de la YMCA
Cuartel de Vancouver, 1917
[Fuente: Old Pictures]
4 comentarios Decíamos en el texto anterior, Blogs y Power Laws: Bienvenido a la Larga Cola, que la Larga Cola tenía un comportamiento fractal, lo que significaba que si escogíamos una pequeña sección de ésta y la estudiásemos, lo que obtendríamos sería, invariablemente, una pequeña Larga Cola. Tratando de comprobar si esto era así, lo que hemos querido realizar ha sido un experimento, localizando una Larga Cola y analizando una de sus características.
Lo analizado: El número de suscriptores de un feed de un blog
Sinceramente, nos lo hemos puesto un poco difícil porque hemos escogido como valor a estudiar el número de suscriptores que tiene un blog. Anteriormente, era bastante complicado estudiar el número de personas que podía estar apuntada a un feed, puesto que los gestores de contenido de las bitácoras generaban el código correspondiente de forma automática y no había forma de saber el número de lectores que un blog disponía a través de sus feeds ni siquiera para los autores de un blog. Sin embargo, la aparición del servicio Feedburner permitió, además de personalizar los feeds de los weblogs, añadir nuevas posibilidades a estos como las estadísticas de uso. De este modo, Feedburner permite que conozcamos el número de suscriptores mediante un pequeño código, tal como os señalamos en nuestra página de estadísticas.
Obviamente, para poder analizar el comportamiento fractal de una Larga Cola, debemos disponer de una y poder estudiar una sección de ésta. Nuestra elección ha sido el Ranking de blogs en español que es, obviamente, una Larga Cola de bitácoras – No son todas las que son, por supuesto -. El siguiente paso ha sido escoger la cabeza de la cola, los 100 primeros blogs de su ranking confiando que el resultado fuese positivo.
Debemos señalar que el cómo estructura esta página su ranking no se debe tan sólo a una sola variable, el cómo otorga los distintos pesos a las distintas variables para el establecimiento de las posiciones dentro del ranking está explicado en su FAQ, pero el valor que nosotros buscábamos el número de suscriptores a través de Feedburner se encuentra publicado en cada página personalizada de cada bitácora. Así, por ejemplo, hoy, este blog se encuentra en la posición 210 sobre un total de 4806 blogs hispanos disponiendo de distintos rankings y valores. Todos son consultables como nuestro Pagerank, los enlaces que ha detectado Technorati, el número de suscriptores de FeedBurner, así cómo el número de enlaces que el bot del sitio web ha detectado, como los datos de Google, Google Blog Search y Yahoo! Search.
Por otro lado, es cierto que no todos los blogs utilizan este servicio para ofrecer un feed estandarizado y universal, pero de las 100 bitácoras estudiadas sólo 14 no utilizaban este servicio, y algunas muy veteranas como MiniD. Nuestro interés sobre el número de suscriptores se debe a que los datos no son manipulables, es decir, en general, son personas las que deciden suscribirse a un feed, por lo que se asegura cierto número de lectores fijos sin que el autor de un blog pueda hacer mucho por aumentar o disminuir sus lectores. Es obvio que un suscriptor puede suscribirse en varias ocasiones a un mismo feed utilizando sistemas distintos, por ejemplo a través de dos lectores RSS basados en web, pero consideramos que los datos se refieren en su mayor parte a un lector por suscripción.
Yo acepté el caos, pero no estoy seguro
de que él me acepte a mí.
Bob Dylan
Una de las curiosidades de la Larga Cola (Long Tail) es que tiene un comportamiento fractal, es decir, si cogemos una sección de ella y la observamos, nos percataremos que es invariablemente una pequeña Larga Cola. Tomemos un ejemplo cercano: La Biblioblogosfera. Si dispusiésemos todas las bitácoras que se publican en la blogosfera y las agrupásemos por temáticas, descubriríamos sin lugar a dudas que hay una mayor cantidad de weblogs que se dedican a un tema específico muy popular, mientras que le seguirían las distintas temáticas que se distribuirían en forma de larga cola. Así, si escogiésemos una pequeña sección de esa cola, por ejemplo, las bitácoras dedicadas a la biblioteconomía y documentación, y mirásemos su temática, también descubriríamos que se organizan siguiendo una larga cola.
La Larga Cola en la Biblioblogosfera
Cuando la Biblioblogosfera estaba en su fase incipiente, todavía no había sido ni bautizada, Bárbara Flores y Elisa Legerén realizaron y publicaron un estudio que llevaba por título: El Fenómeno Weblog como nuevo medio de comunicación y su incidencia en Biblioteconomía y Documentación que analizaba la distribución de la comunidad de weblogs con temática relativa a la Biblioteconomía; de forma que establecieron un ranking de bitácoras más influyentes. Para establecer la ordenación de los sitios web, lo que sus autoras hicieron fue analizar el número de enlaces que los distintos blogs de esta temática se realizaban entre sí conformando una comunidad.
De este modo, si nos detuviésemos en analizar los gráficos que se derivaron de ese estudio descubriríamos que las cinco primeras posiciones congregan el 80% de los enlaces entrantes que se producían dentro de la comunidad de bitácoras. Siendo menos científicos, por otro lado, si consultásemos los textos y gráficos que redactamos en este mismo blog para el análisis de la biblioblogosfera también podríamos comprobar que, aproximadamente, el 20% de las bitácoras analizadas congregaban el 80% de los enlaces entrantes entre ellas (Ley de Pareto).
La ley de potencias se cumplía de una forma exacta a pesar de que, como siempre, hubo controversias de cómo se había establecido un ranking y cómo se había valorado los enlaces. Además de enfrentarnos con la realidad de que si en una pequeña comunidad de vecinos sucede que se discute sobre cómo se valora y se da peso a un blog, podemos imaginar lo que sucede a una mayor escala y de una forma más global: La blogosfera.
Hace poco os comentamos que Google aparentemente nos había penalizado, para la composición de aquel texto me dispuse a hallar la cuota de mercado y, por tanto, la penetración que tenía Google en el mercado español para argumentar nuestra pérdida de visitantes. Lo cierto es que me costó encontrar un dato fiable y, de aquella búsqueda, os ofrecí una cifra inexacta pues afirmé entonces que Google disponía del 90% del mercado de búsquedas en España. Reconozco que rebajé un poco la cuota, puesto que según se afirma en el artículo Google y las cuotas de mercado el porcentaje se sitúa en un 99%.
Sinceramente, el dato me pareció un tanto escandaloso, ¿dónde quedaba la compentecia (Yahoo, MSN o Ask)? El profesor Enrique Dans en su reciente artículo ¿Es Google un monopolio? detallaba las distintas cuotas de mercado de las que dispone Google, no debemos olvidar que es su principal actividad, en el Globo:
Pero ¿es realmente Google un monopolio? En algunas de las actividades que realiza, como la búsqueda, la pregunta recibe una respuesta diferente según dónde sea planteada. Para un español, un alemán o un holandés, la respuesta es afirmativa: en los tres casos, la penetración de búsquedas hechas en Google supera el 90%. Sin embargo un chino diría que no, dado que Google representa tan solo el 21%, claramente por detrás de Baidu, el buscador dominante. En Japón, la penetración de Google es inferior a la mitad de la que posee Yahoo! En Corea del Sur, Google es prácticamente un desconocido, un competidor completamente minoritario, que sólo se utiliza en un 1.7% de las búsquedas realizadas. En el país más conectado del mundo, Google todavía lo tiene todo por hacer. Aún así, el caso de Corea del Sur, aunque preocupante y prioritario para Google, no deja de ser moderadamente anecdótico: en todo el mundo, el porcentaje de búsquedas realizadas en Google sobre el total ronda el 65%.
Hay quien cree que Google obtuvo su éxito en España, a parte de sus buenos resultados ante las distintas cadenas de búsqueda, debido a la sencillez de su interfaz (Hay que recordar que muchos utilizábamos en España una irrisoria conexión a 56 kbs en plena esfervescencia puntocom) frente a las recargadas páginas de buscadores patrios como el de Terra u Ozú. Debemos señalar que, dependiendo de los estudios a los que acudamos, la cifra puede variar hacia arriba o hacia abajo, aunque nunca descendiendo del 90% de cuota y aclarando nuestras dudas al respecto del poder de Google en la Internet hispana. Así, por ejemplo, desde Webrankinfo nos ofrecen un cuadro con los hábitos de búsqueda de los europeos por países basándose en datos de comScore:
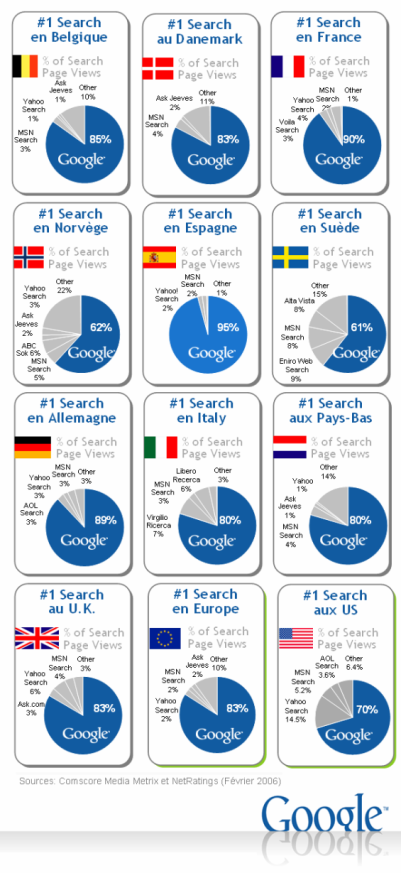
Se afirma que la información es poder y los puntos de a través se accede a ella son importantes. Desde luego que, en España, deberíamos comenzar a plantearnos nuestro hábitos informacionales a la hora de buscar y recuperar documentación en la Red (Y en esto también debemos implicarnos los profesionales de la información) porque no sólo de Google debería de vivir el internauta.